Unified Camera Positional Encoding for Controlled Video Generation
CVPR 2026
Yan-Pei Cao 3 Camilo Cruz Gambardella 1,2 Dinh Phung 1 Jianfei Cai 1
Video
Our UCPE introduces a geometry-consistent alternative to Plücker rays as one of the core contributions, enabling better generalization in Transformers. We hope to inspire future research on camera-aware architectures.
TLDR
🔥 Camera-controlled text-to-video generation, now with intrinsics, distortion and orientation control!


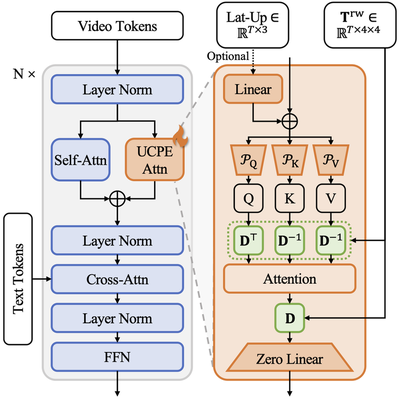
📷 UCPE integrates Relative Ray Encoding—which delivers significantly better generalization than Plücker across diverse camera motion, intrinsics and lens distortions—with Absolute Orientation Encoding for controllable pitch and roll, enabling a unified camera representation for Transformers and state-of-the-art camera-controlled video generation with just 0.5% extra parameters (35.5M over the 7.3B parameters of the base model)

Highlights
Our Relative Ray Encoding not only generalizes to but also enables controllability over a wide range of camera intrinsics and lens distortions.

Its geometry-consistent design further allows strong generalization and controllability over diverse camera motions.

We also introduce Absolute Orientation Encoding to eliminate the ambiguity in pitch and roll in previous T2V methods.

Abstract
Transformers have emerged as a universal backbone across 3D perception, video generation, and world models for autonomous driving and embodied AI, where understanding camera geometry is essential for grounding visual observations in three-dimensional space. However, existing camera encoding methods often rely on simplified pinhole assumptions, restricting generalization across the diverse intrinsics and lens distortions in real-world cameras. We introduce Relative Ray Encoding, a geometry-consistent representation that unifies complete camera information, including 6-DoF poses, intrinsics, and lens distortions. To evaluate its capability under diverse controllability demands, we adopt camera-controlled text-to-video generation as a testbed task. Within this setting, we further identify pitch and roll as two components effective for Absolute Orientation Encoding, enabling full control over the initial camera orientation. Together, these designs form UCPE (Unified Camera Positional Encoding), which integrates into a pretrained video Diffusion Transformer through a lightweight spatial attention adapter, adding less than 1% trainable parameters while achieving state-of-the-art camera controllability and visual fidelity. To facilitate systematic training and evaluation, we construct a large video dataset covering a wide range of camera motions and lens types. Extensive experiments validate the effectiveness of UCPE in camera-controllable video generation and highlight its potential as a general camera representation for Transformers across future multi-view, video, and 3D tasks.
Method

Cheng Zhang
Ph.D Student
My research interests include 3D generation, novel view synthesis, image generation etc.