DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-based Optimization
ICCV 2021 Oral
2 State Key Lab of CAD & CG, Zhejiang University 3 Google

Abstract
Panorama images have a much larger field-of-view thus naturally encode enriched scene context information compared to standard perspective images, which however is not well exploited in the previous scene understanding methods. In this paper, we propose a novel method for panoramic 3D scene understanding which recovers the 3D room layout and the shape, pose, position, and semantic category for each object from a single full-view panorama image. In order to fully utilize the rich context information, we design a novel graph neural network based context model to predict the relationship among objects and room layout, and a differentiable relationship-based optimization module to optimize object arrangement with well-designed objective functions on-the-fly. Realizing the existing data are either with incomplete ground truth or overly-simplified scene, we present a new synthetic dataset with good diversity in room layout and furniture placement, and realistic image quality for total panoramic 3D scene understanding. Experiments demonstrate that our method outperforms existing methods on panoramic scene understanding in terms of both geometry accuracy and object arrangement.
Video
Paper



Pipeline
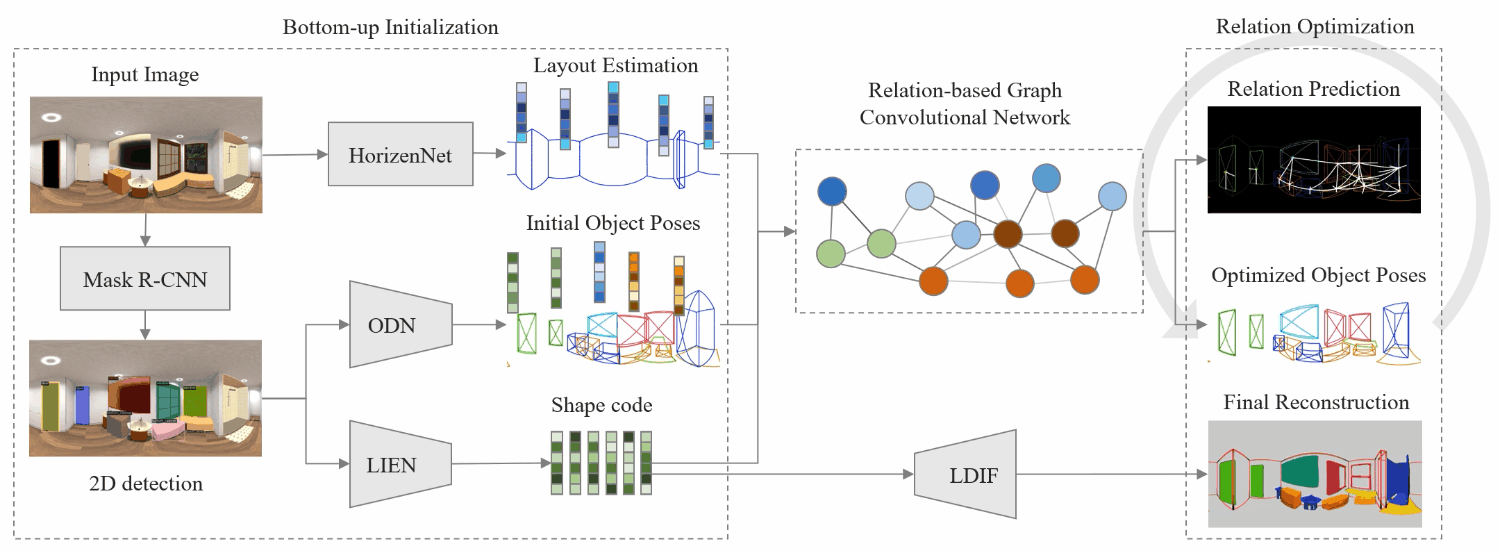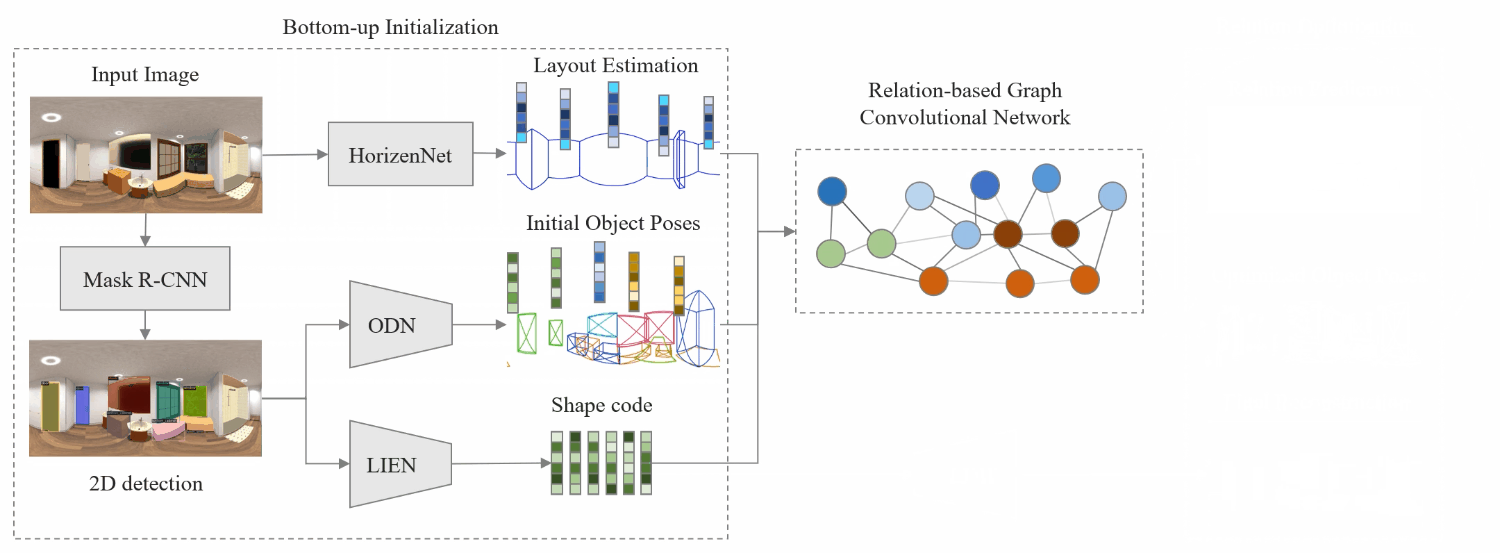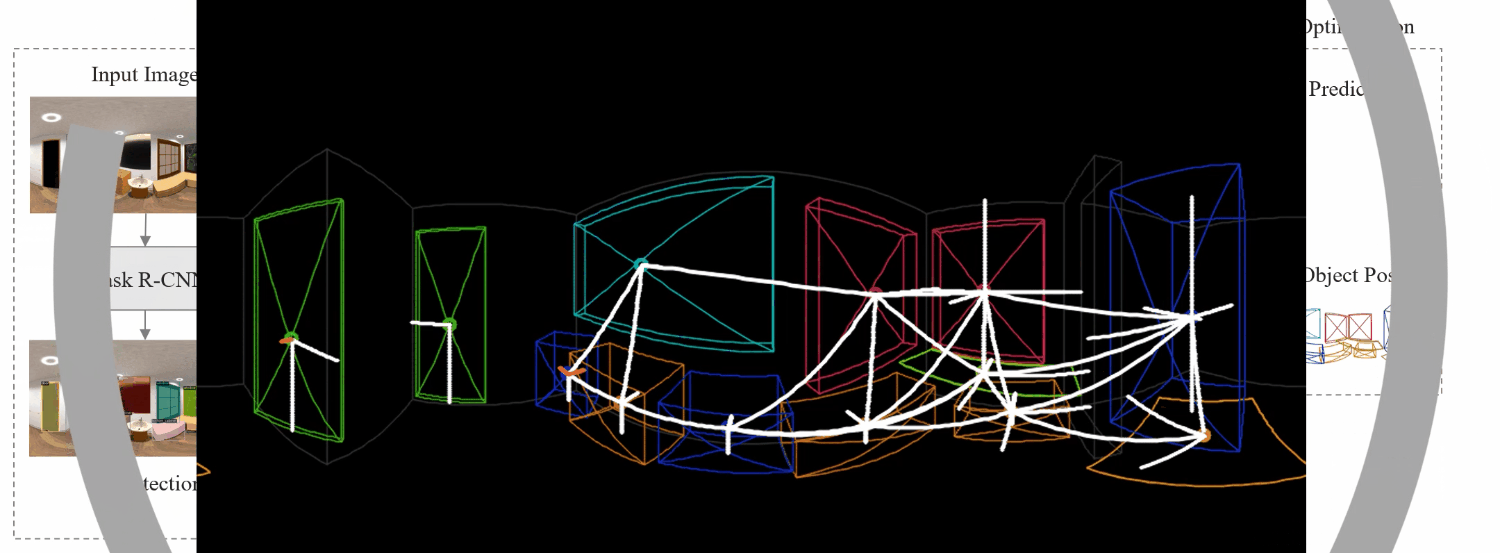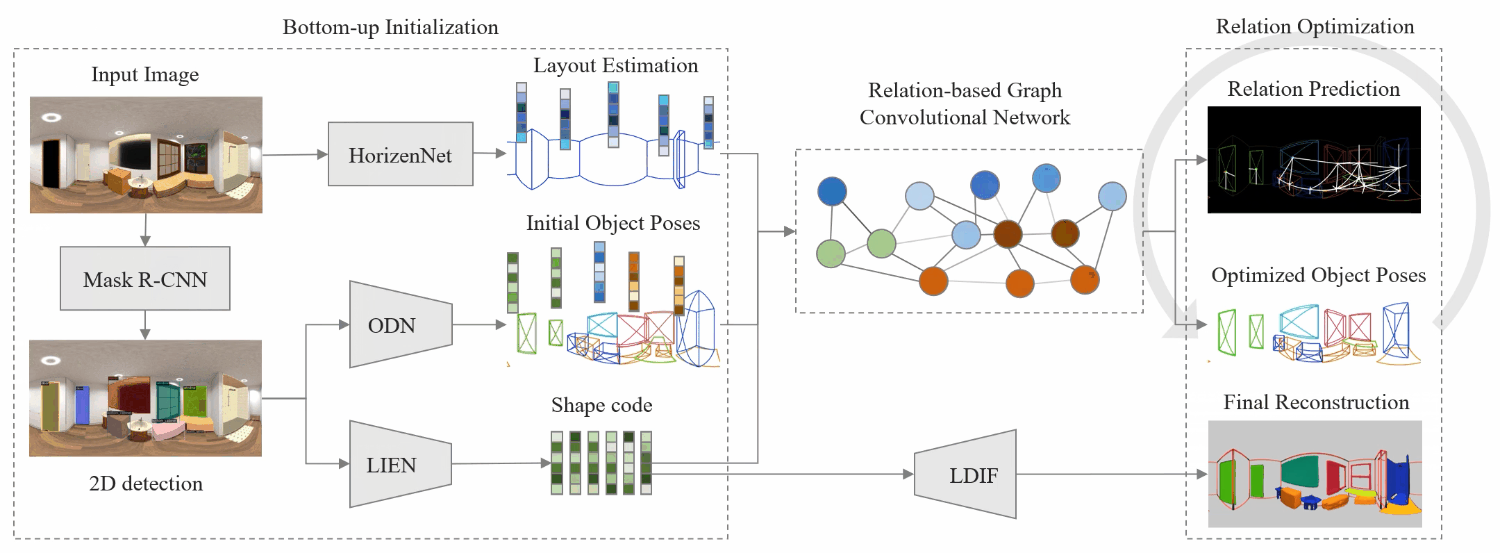
We first extract the whole-room layout under Manhattan World assumption and the initial object estimates including locations, sizes, poses, semantic categories, and latent shape codes. These, along with extracted features, are then fed into the Relation-based Graph Convolutional Network (RGCN) for refinement and to estimate relations among objects and layout simultaneously. Then, a differentiable Relation Optimization (RO) based on physical violation, observation, and relation is proposed to resolve collisions and adjust object poses. Finally, the 3D shape is recovered by feeding the latent shape code into Local Implicit Deep Function (LDIF), and combined with object pose and room layout to achieve total scene understanding.
Interactive Results
Input
Detection and Layout
Reconstruction

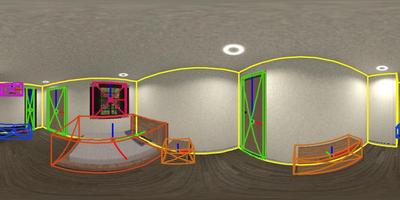







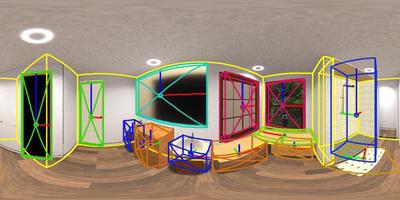
Results

Cheng Zhang
Ph.D Student
My research interests include 3D generation, novel view synthesis, image generation etc.