Holistic 3D Scene Understanding from a Single Image with Implicit Representation
CVPR 2021
2 University of Electronic Science and Technology of China 3 Google 4 ETH Zurich

Abstract
We present a new pipeline for holistic 3D scene understanding from a single image, which could predict object shape, object pose, and scene layout. As it is a highly ill-posed problem, existing methods usually suffer from inaccurate estimation of both shapes and layout especially for the cluttered scene due to the heavy occlusion between objects. We propose to utilize the latest deep implicit representation to solve this challenge. We not only propose an image-based local structured implicit network to improve the object shape estimation, but also refine 3D object pose and scene layout via a novel implicit scene graph neural network that exploits the implicit local object features. A novel physical violation loss is also proposed to avoid incorrect context between objects. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of object shape, scene layout estimation, and 3D object detection.
Video
Paper



Motivations
- Implicit representation like Signed Distance Function (SDF) can be used to detect collision and propagate gradients
- And together with structured representation (LDIF), the shapes can be learned better and more shape priors can be provided for relationship understanding
- Graph Convolutional Network (GCN) is proven to be good at resolving context information in the task of scene graph generation
Pipeline
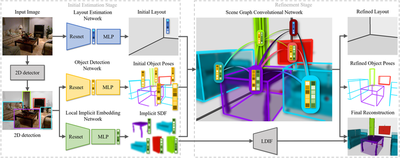
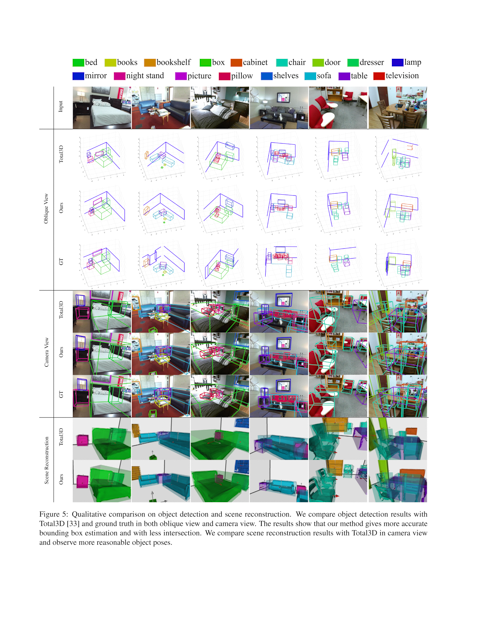
The proposed system consists of two stages, i.e., the initial estimation stage, and the refinement stage. In the initial estimation stage, a 2D detector is first adopted to extract the 2D bounding box from the input image, followed by an Object Detection Network (ODN) to recover the object poses as 3D bounding boxes and a new Local Implicit Embedding Network (LIEN) to extract the implicit local shape information from the image directly, which can further be decoded to infer 3D geometry. The input image is also fed into a Layout Estimation Network (LEN) to produce a 3D layout bounding box and relative camera pose. In the refinement stage, a novel Scene Graph Convolutional Network (SGCN) is designed to refine the initial predictions via the scene context information.
Interactive Results
Input
Total3D
Ours






Results

Cheng Zhang
Ph.D Student
My research interests include 3D generation, novel view synthesis, image generation etc.